
Through my journey of building Domain Models I had good and bad experiences that today I share with you to save a few hours of your development time. These are opinionated approaches that I follow when building Rich Domain Models. A Rich Domain Model is the technical part when applying DDD, it envolves the building blocks like Entity, Value Objects and Aggregate Root. The goal is to build a ubiquitous language between developers and stakeholders using the a vocabulary that describes the business rules. What are the business rules? Its what’s make or save money, irrespective of whether they were implemented on a computer or manually. This kind of rules are simple to be described in words as they do not require a database, in fact the database is just an IO device that our software requires to persist state. We could say the same about the Web, it is only a delivery mechanism to present information to our users and has nothing to do with the business rules. Having that clear is my way of thinking but what I find in our industry is a spaghetti of business rules, persistence libraries and frameworks code. In the next few topics I’m going to expose code issues we want to avoid before you decide to invest time building rich domains models . The code issues I am referring to are known as code smells, and they are associated with architecture and development problems.
Code Smells to Avoid
The opposite of the Rich Domain Models are the Anemic Domain Models, in this second one the business logic are implemented far from the classes that own the data, it brings low cohesion and nonexistent encapsulation. The next topics introduce common code smells related to Anemic Domain Models.
Feature Envy
It’s the situation where a client class access the fields of another class more than it’s own data. In order to keep the policies of the second class consistent the consumer needs to validate and manipulate multiple fields together. This code smell is easy to find when “Application Services” or “Extension Methods” are envy of other Entities fields. These application services implement the policies that should be managed by the Entities classes. Just like this: 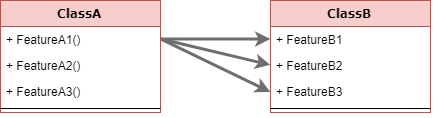 The solution for this code smell is to move the envy method into the class that owns the data then hide the internal details.
The solution for this code smell is to move the envy method into the class that owns the data then hide the internal details. 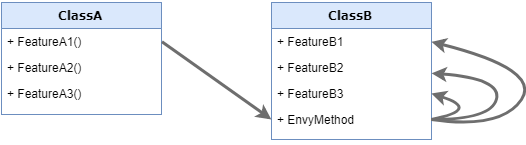
Primitive Obsession
It’s the use of primitive types like string, integer or arrays to ensure the fine grained business rules. As there is no encapsulation, the code get repeatedly validated in different places. These issues are found:
- When “Security Social Numbers”, “Phone numbers” or Money are repeatedly validated from the UI through the database.
- When a client class needs to manipulate arrays of other classes in order to keep the data and policies consistent. At first having methods to manipulate arrays everywhere (eg. linq) seems an advantage. Then the different places do not implement in the same way, or you need a big effort to maintain it consistent.
- The generic arrays and collections leaks abstraction, they provide access to language specific methods instead of the methods known by the ubiquitous language.
To fix this issue we need to create a value object that encapsulate the fine grained business logic and for collections we should use the adapter pattern with the proper methods to manipulate the items.
Public Setters Abuse
This is far the most common code smell seen in .NET applications, I guess is due to the Entity Framework popularity and its code samples and patterns that exposes every entity properties. To clarify the problem I share the fundamentals of object-oriented programming language, its encapsulation.
When composing objects into a new type, we want the new type to exhibit simpler behavior than all of it’s component parts considered together. Steve Freeman (GOOS)
Let’s suppose that a entity have three properties and they are all public exposed. So there is no encapsulation, the complete complexity of the class are the equals as all internal fields. It allows the consumers to change the internal fields at any time anywhere. The consumers need to understand how to change the properties and to maintain the state consistent. This code issue are seen together with business classes been designed to meet the ORM frameworks restrictions. The end result are classes that only reflect the tables structure. To fix this issue we need to remove the public setters and move the logic to and create new methods.
Anemic Classes
It’s the photograph of a poor implemented business requirements. This kind of classes only store data, they do not implement behaviors or policies. How to fix that? Not simple answer but you need to start thinking on:
If you are calling two setters in a row, you are missing a concept (Oliver Gierke)
These code smells alone doesn’t mean that the code is bad at all. In certain conditions these characteristics are necessary. The problem happens when multiple code smells are combined in a single code base, then the software gets harder to change, the regression tests are required for small changes and the bugs are frequent. Let’s build a new mindset, the journey is worth it!
How to Enrich Domain Models?
I begin following TDD practices, it gives me confidence to enrich the model in different places incrementally. I know two TDD approaches, the inside-out and the outside-in. And to be honest I prefer the inside-out approach, with the guidance of DDD building blocks. The DDD building blocks guides me in the correct path. I start thinking on Entities, Value Objects and Aggregates then I move outside to the Use Cases and Repositories. I am able to discover a lot of domain, design the model without working on database and UI. Next, a short description of what we gonna need from DDD.
- Value Objects: its immutable custom types that are distinguishable only by the state of its properties.
- Entities: its custom types that are distinguishable by an identity property, it has data and behaviors.
- Aggregate roots: a kind on entity that maintain the object graph in consistent state and is associated to a repository.
- Use Cases: coordinates the operations with the domain objects and services.
- Repositories and Services: provides access to external resources.
We are going to learn by example, next you see some business rules then the implementation. To design a Rich Model we need to concern only on business policies, all the external details like databases, HTTP and serialization will be addressed later. In our example, we define the business with the following use cases and requirements:
- The customer can register a new account.
- Allow to deposit into an existing account.
- Allow to withdraw from an existing account.
- Accounts can be closed only if they have zero balance.
- Accounts does not allow to withdraw more than the current account balance.
- Allow to get the account details.
- Allow to get the customer details.
- It’s required from the customer to fill Name, SSN and to deposit an initial amount when registering.
We could identify the following DDD patterns for these business: 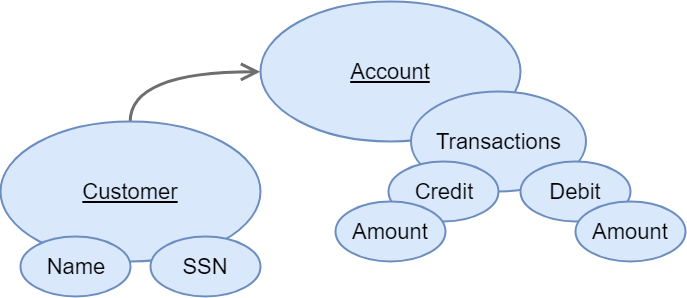
- Aggregate Roots: Customer and Account.
- Entities: Credit and Debit.
- Value Objects: Name, SSN and Amount.
- Use Cases: Register, Deposit, Withdraw, Close, Get Customer Details, Get Account Details.
We warn you that our model are persistent ignorant, it privileges the business and we avoid ORM frameworks interference in our classes. To design the Customer we think first on the test specification.
CustomerTests.cs
We point out that the Customer and Account are aggregate roots and they only know each other by their IDs. The Customer.Register(..) method does not accept the Account instance, instead accepts only the AccountId.
Customer.cs
All fields are private set so all the state changes are made by the methods, the specific Accounts property return an IReadOnlyCollection to prevent unexpected changes from consumers. In this class the state consistent from the constructor that requires the customer details to the Register(..) method. Previously, I said that I would not corrupt the Model in order to persist the entities state. I made and exception for the factory method that receives the complete Customer fields then it creates a Customer instance.
To persist the objects graph the repository can read the public properties.
Account.cs
I added the sealed modifier to the Account class to prevent inheritance. I am an advocate of composition over inheritance, and I added this modifier to the domain classes to be clear with my intention. I don’t want to allow consumers to create unnecessary coupling. The transaction history can be modified only in the next situations:
- By the deposit method which adds and transaction.
- By the withdraw method which adds and transaction.
- By the factory method which recreates the list.
The consistency is ensured by not allowing the client to make changes on the TransactionCollection property.
SSN.cs
This class is a value object for the Swedish Personnummer and it encapsulates the complexity of validating the string format. Whenever I refer to a string personnummer I can use this class.
Source Code
There are more examples of Rich Domain in my GitHub repository. You can find the Aggregates, Entities and the Values objects. Also everything is covered by Unit Tests. The source code is available on GitHub DDD/TDD Rich Domain.
git clone https://github.com/ivanpaulovich/ddd-tdd-rich-domain.git
cd ddd-tdd-rich-domain
./build.sh
Give it a stargazer, fork it if you like.
Conclusion
Building rich domains is not an easy task, in fact it requires much more effort to implement the business requirements and how to hide the internal details. Fortunately we can leverage on TDD practices to validate the API usage, and to ensure it’s correctness. The DDD patterns help us understand how the components should work together. We highlight that the principles of high cohesion and low coupling are required to lower the complexity of the code base. Have you implemented a Rich Domain Model? How was your experience? Leave your feedback.